
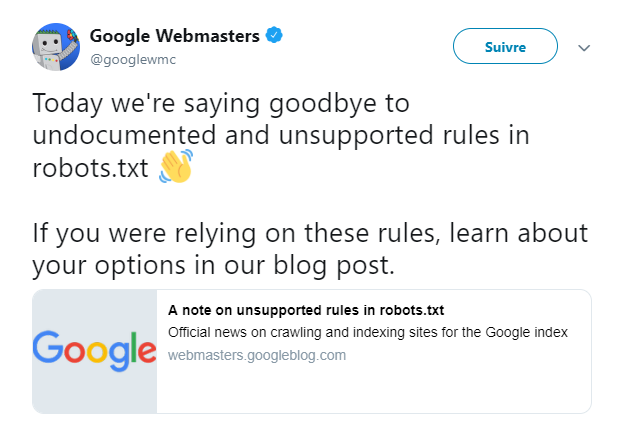
Mardi 2 juillet, un tweet du compte Google Webmaster a fait réagir les webmasters et spécialistes SEO. En effet, L’entreprise américaine a annoncé que son moteur de recherche n’interpréterait plus les directives non documentées dans le fichier robots.txt à partir du 1er septembre 2019. Au revoir les directives nofollow et noindex ! Ça ne vous dit rien ? On vous explique tout !
Le fichier robots.txt a été créé par le webmaster Martijn Koster en 1994 et est basé sur le Robots Exclusion Protocol (REP). Le robots.txt est un fichier texte placé à la racine de votre site web. Ce fichier est destiné à interdire aux robots des moteurs de recherche l’indexation de certaines zones de votre site internet. C’est également le premier fichier analysé par les spiders (robots).
Concrètement, ce fichier permet d’empêcher l’exploration (accès) et l’indexation (apparition dans les résultats de recherches) de certaines pages, groupes de pages voire du site entier par les robots des moteurs de recherches. Nous l’utilisons fréquemment dans nos campagnes d’optimisation, notamment pour améliorer le budget crawl, prioriser le contenu utile et éviter le duplicate. Ce fichier permet également d’indiquer aux moteurs le fichier sitemap.
Pour savoir si vous possédez un fichier robots.txt, il suffit de taper :
https://www.adressedevotresite.com/robots.txt.
Si le fichier est présent il s’affichera, s’il n’existe pas une erreur 404 s’affichera.
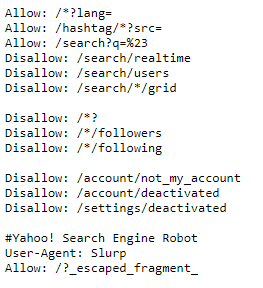
Capture d’écran d’une partie de https://www.twitter.com/robots.txt
La modification du Robots Exclusion Protocol (REP)
Google cherche à obtenir un standard officiel pour le protocole d’interprétation des robots.txt. Actuellement, bien qu’utile, ce document n’a pas de réglementation concernant les directives comme la balise noindex.
Cette standardisation est une bonne chose pour les développeurs comme pour les experts SEO car elle permet de clarifier les informations prises en compte par les moteurs de recherche et facilite la compréhension pour ses utilisateurs.
L’entreprise américaine a rendu public ce mardi 02/07 qu’ils avaient créé un document sur la façon dont le fichier robots.txt est utilisé et l’ont soumis à l’IETF (internet Engineering Task Force). Ce travail a été réalisé grâce à l’aide du rédacteur initial, des webmasters, et d’autres moteurs de recherches.
Parmi les propositions faites à ce niveau, on peut identifier celles-ci :
- Tout protocole de transfert peut utiliser robots.txt. Il ne serait plus limité à HTTP(S) et pourrait également être utilisé pour FTP (File Transfer Protocol) ou CoAP (Constrained Application Protocol). Cela signifie que le robots.txt pourra être utilisé pour des logiciels de transfert de donnée comme Filezilla, qui peuvent par exemple alimenter un serveur en contenu, mais également pour l’internet des objets, donnant une nouvelle dimension au robots.txt.

- Le temps de cache (copie d’un site pouvant être récupérée sur des serveurs) sera limité à 24h en l’absence de directive. Par exemple, pour un protocole http, un métatag « cache-control » dans le header permet de modifier ce délai. La modification du robots.txt sera prise en compte plus rapidement, la mise à jour du côté moteur de recherche étant plus régulière.
Ce document doit être débattu au sein de l’Internet Engineering Task Force (IETF) avant toute modification du REP, les changements listés ne sont donc pas encore effectifs.
La mise au point de Google
A partir du 1er septembre, les directives crawl-delay, le nofollow et le noindex ne seront plus prises en compte par Google.
Toutefois, il est toujours possible d’insérer un métatag noindex dans le header des pages ciblées pour déclarer une page ou un répertoire en noindex et refuser l’indexation.

Attention, utiliser la directive disallow (qui empêche le passage des robots de Google sur une page) ne garantit pas que celle-ci ne sera pas indexée. Dans de très rares cas, Google pourra toujours indexer une page s’il repère un lien vers cette page. C’est pourquoi il vaut mieux utiliser la métatag noindex.
Conséquences sur l’indexation des pages de votre site web
Avec ces indications, Google précise bien que le robots.txt sera analysé différemment, tendant ainsi vers une uniformisation du web. Avec la demande de création d’un dossier unique soumis à l’IETF et l’arrêt d’utilisation de consignes non reconnues officiellement, l’objectif de Google est clair : aller vers un standard qui évite des surprises aux webmasters en fonction des robots d’indexation.
Pensez donc à modifier vos robots.txt avant le 31 août pour être tranquille ! Nous pouvons vous aider, contactez-nous !